As we transitioned to math activities that were more engaging for my kiddo, I started to notice similarities and patterns. At this point, I was using the book Moebius Noodles as our primary inspiration for math activities. For example, we would have a lot of fun playing around with body symmetry exercises, where one person mirrored the other. We would estimate height by guessing and then building a tower with Duplo blocks. The tower would inevitably collapse, leading to lessons about structure and making a solid base. We played a “program Dad” game where he would direct me around the house by telling me exactly what to do. We found that using a checkerboard tile exercise mat helped a lot. For example, kiddo would tell me to move forward three squares, then turn one square to the right. We played around with grids, working with numbers or drawing items within the shape.
I am a programmer, so playing with grids make me think of arrays. Arrays are used a lot in programming languages as handy data structures. You can use them to store and access objects that you want to interact with in a computer program. When I was learning about arrays in programming, I found simple examples made sense, but when you added more dimensions or started thinking about performance, I struggled. I had trouble with thinking in abstractions. It took a long time to overcome that. The actual concepts, code and mathematics were simple, but my brain struggled to think about something virtual with different dimensions. Similarly, when I started a linear algebra course, I spent too much brain power getting my head wrapped around how arrays were formed, and keeping track of what number was in what row or column. The actual math was often elementary level, but the abstractions were difficult to grok. I felt that adding in thinking about more than one dimension, and thinking about abstractions in math would help my kiddo develop better math skills. If he could get used to thinking about abstractions I wasn’t exposed to until I was in my late teens, what would that do to his problem solving brain?
We would also look for array patterns around the house. We would examine Duplo and Lego bricks, muffin tins, egg cartons, game boards, crayon organizers, drink holders, watercolor paint trays… the list goes on. There are array shapes everywhere, and we would find them and discuss them. What pattern do they make? What could we call this in math or programming? Soon, kiddo was spotting array patterns himself and pointing them out. Next, I wanted to add a bit of structure to his thinking about arrays. To make things more interesting, I would ask him to identify the rows (horizontal) and the columns (vertical). We would play around with that concept. For example with an egg tray, it is natural to set it down so that it has more columns than rows, because that is how it is labeled. But what happens if we turn it so it has more rows than columns? We would identify an egg and its location: 3rd row, 2nd column, and then move the egg tray. Now it is 2nd row, 3rd column. Did the egg change, or did the “address” of the egg change? Turns out the egg is the same, but the way we describe to find that exact egg can change, depending on our perspective.
Games and Arrays
Since kiddo could easily count to 30, he could easily keep track of rows and columns in a 10×10 array. I printed out a 10×10 checkerboard and we started to play with it. I would ask him to help me determine where the rows and columns were. This took some practice, and I told him that when I was taking linear algebra in university, and then later when I worked with tables in HTML, I would remember that columns were vertical, like columns holding up a roof. Rows I remembered as horizontal, like rows on the ground in a vegetable garden. Columns hold up, rows are planted on the side. Next, we would count, making sure we kept track of the row number and the column number, which is the “address” or location in the array. Once kiddo could identify rows and columns on his own, and find a location when prompted, we started to add complexity.
I would set the checkerboard down, and ask him to locate row 2, column 3. He would take his finger, and count down to row 2, and then he would move his finger 3 spots over. While my brain was thinking of patterns in applied math, his brain was spotting a familiar pattern: games. We transitioned from counting and pointing to making simple games together. Every morning, we would take out the checkerboard, and we added in dice and game play pieces. Using dice meant I needed to expand the size of our array to 12×12. Next, for playing pieces we found Lego bricks, bingo chips, and other objects worked, but we settled on mini ring fidgets. These worked best because they weren’t associated with anything else that distracted us. From there, we would take turns rolling a single die. We both started at top left, just off of the grid, and after a roll, you would count forward to match the number on the die and move your playing piece to that position. We would move row by row from beginning to end. The first person to get to the end won.
Next, we added a die so we had a pair, and rolled both dice at once. The number on the left most die represented the row, while the next number represented the column. Instead of moving through the game board from the first column and moving through from row to row, you had to keep track of the row/column pair. This added a lot of randomization, and could cause someone who was “winning” to get knocked back. Now we were thinking and playing and having more fun. To add more randomization and surprise, kiddo would add in extra objects. If you landed on a Lego brick, you had to count the rows/columns of the brick and move to that spot on the board. If you landed on a different colored fidget ring, you had to start over. If you landed on a smiley face sticker, you could skip to the end. Now we were having a lot more fun, but it was hard to “win” because of all the randomization. To move beyond this, I added in two variations. The first was to get him to create the activities from scratch, and the second was to add in zero-based counting.
We were playing with the emerging array game every weekday morning. We would set up on the floor, and we would play around and have fun. When it started to get stale, I asked him to run the sessions. At first, I just had him tell me the rules of the game, and explain how everything worked. It was often muddled, the rules would change to favor kiddo and disadvantage dad, and the lessons about arrays were completely lost. However, I was pushing for engagement rather than mastery, so I didn’t care. On days when I ran the game, we did it according to rows and columns and reviewed what we knew about arrays. On days he led the array games, whatever happened was what was supposed to happen that day.
At first I was concerned he wasn’t taking anything away from the lessons, but when we played the game the way I had set up, he seemed to grasp the concepts more firmly. The random play was reinforcing what I was hoping he would learn. Even though he wasn’t playing by “the rules”, he was exploring the boundaries and being creative. Math lessons aside, creativity with designing your own game with dad has tremendous value on its own. It was actually reinforcing the lessons, even though it didn’t seem like it at first. He was truly owning the concept and chasing down ideas he had as things in the lesson reminded him of games we played, video games, following recipes in the kitchen, etc. There were also disagreements and lessons about playing fair, being a good sport, and other important issues. It was hard at first to not correct and bring him back to the topic at hand, but I found his brain was working on it, even if I didn’t see it at first. If I could just shut up and be a 5 year old with him in the moment, good things came out of it. I realized he was doing what I was hoping for anyway, he was applying the math. He was taking the theory and making it real.
The next variation was to make it more difficult, and to keep track of rows and columns using zero-based counting. One of my frustrations when I was programming was having to switch my brain from starting at “1” to starting at “0”. Many programming languages use zero as the first number, and I found it hard to adapt at first. When I taught adults to program later on, many also struggled with this. Instead of using your programming brain, you were expending energy trying to count to 10 starting at 0. With kiddo, I am a stickler for starting counts at zero, not one. It makes everything easier for him to have that solid grasp of zero. It helped him with place values, with counting, and it helps him with simple arithmetic. Understanding zero also helps with abstract concepts as well. Since he was familiar with starting to count with zero, and using place values to increase or decrease, transitioning from 1 to 0 based counting for arrays wasn’t that much of a stretch.
Arrays and Muffin Tins
To make this come alive, I looked for kid friendly array activities to explain this better than I could. Unfortunately, I couldn’t find anything online other than identifying arrays and looking at rows and columns. Good activities, but not what I wanted. I wanted kiddo to start thinking about arrays as an abstraction, but add the realism by keeping track of rows and columns to access something stored at each address. I wondered about a cardboard fold out activity, like a mailbox. I talked to a programmer friend, and she said her daughter had worked on a “muffin tin” math activity. Each indentation in the pan was covered with cardboard, and the kiddos would take the top off to discover items in each section of the tin. This is easy enough to do, why couldn’t I do that with arrays?
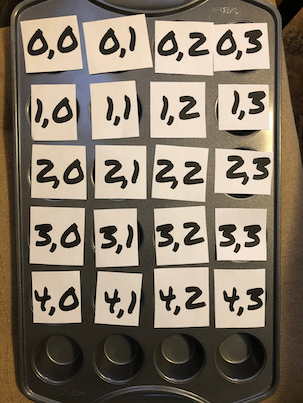
With a bit of thought, I came up with a simple activity. I printed out slips of paper with a pair of numbers to represent the row and column, which would cover the indentations of a muffin tin. Under each address, within the muffin tin indentations, I put in a small toy. I started with Lego pieces and one Lego character. Next, I asked kiddo to find the Lego character. He needed to lift up the paper that had the row/column location, look underneath, then put it back and move on. Finally, he found the Lego character. I asked him what row and column he found the character at. Unfortunately, the location papers were scattered, so we repeated the activity, but with more care this time. To add interest, I changed the location of the character, and asked him to write down the row and column on the paper, once he had found the character again. This time, it worked. He was starting to engage. To increase engagement, I turned my back, and asked him to put the character in a new location, and then I would have to find it. He started to have fun.
Kiddo hid the Lego character at a location, and put the paper locations back on top of each indentation. Trouble was, they were out of order. Instead of pointing this out, I pointed along with my finger by moving by address, rather than physical location. Instead of starting at the top corner where 0,0 should be, I started where 0,0 actually was placed, which was somewhere else on the tin. Next I found 0,1, then 0,2 and so on. Some where in the correct location, but some were not. I feigned surprise and said I was confused. Kiddo patiently explained I should start at the top and work my way down. I suggested that if that was the case, he needed to make sure the addresses of each tin indentation was in order. He quickly shuffled the papers around so that the muffin tin rows/columns matched correctly. I then started and worked my way through until I found the Lego character.
We took turns with this activity several times, and he had lots of fun. He would try to surprise me with the location of the Lego character by putting it in the last position so I had to count all the way to the end, or at the beginning so I found it right away. He would put it back in the same location, or he would try to distract me by saying something funny while I was moving through each item. There was a lot of giggling, and when the papers with the row/column addresses got mixed up, he was quick to help sort them again.
The next day, I asked him to set up the muffin tin activity. His job was to put items in each indentation, and then put the correct address slip of paper over top, in order. We had a couple of oopses with 0,0 and 3,4, but with some clarification he remembered how it worked. This time however, we got Mom to hide the Lego character, and then we took turns trying to find it. To begin, we both started at the top left and worked our way through. The next time though, I surprised him with an algorithm. When it was my turn, I didn’t start at the beginning, I started at the end. Then I switched back to the beginning, then back again and so on. I found the Lego character first, since I was using a consistent approach. Next, I checked at the end, then the middle, and then moved back and forth from middle to end, and once again, I found the Lego character first. Kiddo was disappointed and feeling a bit frustrated that I was winning. He accused me of cheating.
This turned into a wonderful teachable moment where I could explain algorithms.
How do you explain algorithms to a 5 year old? The simplest way to describe it for him was that it was a set of steps to solve a problem. We looked at recipes for food we had prepared together, we looked at Lego instructions, and we looked at simple school assignments. Next, I explained what I was doing, that I was using a strategy called Binary search to find the Lego character faster. Since the array is small, it doesn’t give me much of an advantage, but I had lucked out by winning twice in a row. That had piqued his interest. I then explained that he had intuitively used a good algorithm, linear search, and that had worked well. He had started losing the game when he got excited and stopped concentrating. Instead of using a linear search, he was using a random search which is the least efficient. He might choose the same wrong address several times using a random search. That’s not efficient, or as effective. It is more effective and efficient (ie. find the Lego character faster) by using a consistent strategy.
A consistent strategy to solve a problem is another way to think about an algorithm. When you start to lose discipline due to emotions or getting distracted, your problem solving suffers. It’s harder to keep track, it’s easy to forget, and an opponent with a consistent approach will play better.
To reinforce the algorithm idea, we worked together on using each search algorithm. Since it is a small set of data, both linear and binary search were effective. He wanted to try binary search, so we worked together on finding logical places to divide up the data, and then work within those divisions. For example, he might look at the last address first, then look at the middle address. Next, he would move between those two addresses with each turn. He might then change tactics and try a linear search from the first address to the middle. This is a bit tricky for a young mind, because kiddo has to keep track of rows and columns, as well as the artificial divisions we were making in the grid of the array. To help keep track, we used pencils or longer Lego pieces as placeholders.
After a few days, kiddo was doing really well with the muffin tin array game. He was using a strategy to choose an algorithm, and he was comfortable with zero based counting. One day I sat back and watched him. I felt amazement and joy watching him. Not only was he demonstrating a basic understanding of arrays, but he was thinking about computer programming on his own terms. This applied math, or the “why” is absolutely crucial in learning. It was within his skill level, it was relevant to his interests, and it was fun for him.
We do programming work because kiddo has an interest in it. The TedEd Think Like a Coder series was particularly interesting to him. He had discovered this series on his own, and he looked forward to new episodes when they were released. Each episode prompted a lot of discussions about coding and me trying to replicate what they were doing in the story for him on my own PC. Sometimes I would struggle, and remembering to show him my mistakes, we would talk about how my code wasn’t working, or when I needed to look something up or ask for help from a colleague with better coding skills.
Programming is also an easy place for me to answer applied math questions, and to talk about day in the life applications of math. Sometimes the only way I can start to answer a “why do we do this” question is by working it out in code to show him an example. No, we don’t learn math for no reason at all. Yes, some people work with math every day.
Making it Real With Code
Looking at array addresses of rows and columns as zeroes felt arbitrary to kiddo. While he understood it and got it right most of the time, it really felt like one of those “grown up” things that didn’t make a lot of sense. Isn’t zero just another way to describe “nothing”? To help with this, we worked together on our home address vs. that number represented as a quantity. Next, we looked at my phone number, and then represented it as a quantity. Then we added some numbers together, which made a sum. What was different? Kiddo explained that the number in our home address and in my phone number stood for something unique, so people could find it or phone me. But a quantity was an amount of objects. A sum was calculating the total of groups of objects. We played around with this concept for a while, and stuck to the idea that an address for your house is a sort of unique label. Our neighborhood has free standing mailboxes that are labelled with a unique number that is assigned for each house address, and the contents are accessed by a key. To get the mail from another part of the world to an individual here, depends on various unique number labels.
Next, we looked at array addresses. We aren’t counting items, we are using the location in an array as a unique label. When we use zero-based counting, “0,0” is the first box in a grid. If we use one-based, “1,1” is the label. But what if we used names? How about emojis? Could we use sounds? Absolutely! We could use anything at all, really. However, number labels that follow a logical pattern work well. They are efficient and effective since they are easily understood.
To take this further, we opened up a language interpreter on my PC called irb, for the programming language Ruby. Kiddo had visited a local fish hatchery, so I typed in the following:
fish_array = ["trout", "pike", "perch"]
I explained that this was a simple array of words for fish. We read through them together I asked if he could help add in more. He suggested “walleye”, “goldeye” and “sturgeon”, so I added them to the array. We now had this array of strings, or words for fish:
fish_array = ["trout", "pike", "perch", "walleye","goldeye", "sturgeon"]
Next, I told him that I was going to use a bit of code to access the first fish in the array. I typed in:
puts fish_array[1]
and the interpreter printed this to the screen:
"pike"
“Aha! Dad! That’s not the first one!”
What do I need to do to fix it?
“You need to type ZERO, NOT ONE!”
I changed the code and tried again.
puts fish_array[0]
the interpreter printed this to the screen:
"trout"
That worked! You fixed the bug!
Kiddo really enjoyed this. We were controlling the computer, and it was important to keep track of what you were doing, because one simple error could give you the wrong answer. I explained that in computer programming, we often call this an off by one error.
We played around with this for a while, adding in array indexes that didn’t exist, to see what error would be produced. Then, I created a larger array, and used an iterator to print through each item, rather than typing in an address. Kiddo liked the idea of looping, we could do things quickly and efficiently, and you didn’t necessarily have to figure it out yourself, you could get the computer to determine what was correct for you.
We had fun. He wasn’t learning these concepts, but I was exposing him to some simple programming basics and explaining what we were doing. He had opinions and ideas about the content of arrays, and what to print out, and I would follow his lead by adding in conditionals, branching, etc. He then asked an interesting question. Essentially, he wanted to know if we could have an array that was made up of arrays. “Of course!”
I muddled around in the code to generate an array made up of arrays, and showed him how we accessed elements in an array of arrays. This started to look to him like our muffin tin game, since we needed to keep track of more than one index or address number. After a while, we had the code looping through each array within the array and printing things out, but that was getting complex and he was getting tired.
I sat back and I felt a bit shocked. Here we were, playing around with concepts I had struggled to learn when I was nineteen or twenty, and my 5 year old kiddo had grokked the basics. He could follow the form, he could play and have fun, and he understood that things could be stored in arrays, whether they were in muffin tins or mailboxes (physical), or in computer memory (virtual).
